Paper Reading - Hekaton: SQL Server’s Memory-Optimized OLTP Engine
Paper summary for Hekaton paper describing SQL Server’s in-memory OLTP database
This is a great paper covering Microsoft Hekaton storage engine. There are a lot of meaty stuff here - lock-free Bw-tree indexing, MVCC, checkpointing, query compilation. I’m especially interested in its query compilation given my background in the .NET runtime and I’ve also spent some non-trivial amount of time focusing on optimizing query performance in my current job. Bw-tree is a very interesting direction for B+ tree as well and we’ll also be looking at a few papers that covers Bw tree in more depth in future posts.
Overview
Hekaton is an alternative SQL server storage engine optimized for main memory (not a separate DBMS). User can enable it by declaring tables to be “optimized”. Hekaton has following designing principles:
- Durability is ensured by logging and checkpointing, but index operations are not logged - they are rebuilt entirely from latest checkpoint and logs. This avoids complex buffer pool flush management.
- Internal data structures (allocators, indexes, transaction map, etc) are all entirely lock-free / latch-free or in any other performace-critical path. Hekaton uses a new optimistic multi-version concurrency control for transaction isolation semantics as well to avoid locking.
- Requests are compiled down to native code. Decisions are made in advance as much as possible to reduce runtime overhead.
Sidebar: Request compilation is especially interesting here. This is a advanced technique commonly seen in language runtimes as JIT. However it is likely in most cases it isn’t quite worth the complexity for DBMS unless memory access (instead of I/O) become the bottleneck when most SQL access data that are hot (in buffer pool cache) and in memory, which definitely is the case here.
Note Hekaton doesn’t support table partitioning. Some in-memory database such as HyPer / H-Store / VoltDB / Dora supports partitioning database by core. However this has the downside when a query can’t be “partition aligned” (not using the partitioning index) needs to be sent to all partitions, and that can be potentially more expensive. To support wider variety of workloads Hekaton decided not to support table partioning. Keep in mind this is partitioning table inside the same database instances, and not related to distributed database where database are partitioned across database instances in different nodes.
In a high-level, Hekaton has 3 components:
- Hekaton storage engine - manages user data and index
- Hekaton compiler - takes AST of stored procedure and metadata input, and compiles to native code
- Hekaton runtime system - integration with SQL server and providing helpers needed by compiled code
Hekaton also heavily leverages existing SQL server services - you can refer to the paper for more details.
Storage and Indexing
Hekaton supports hash index with lock-free hashtable and range-index with Bw-tree (a novel lock-free version of B-tree).
Following table is a good example:
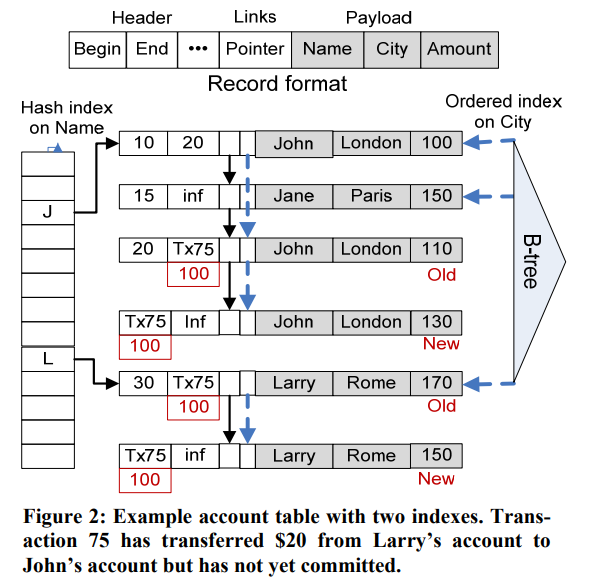
- Both hash-index and Bw-tree index stores pointers to the actual data
- Hash-index are divided by hash-buckets - so bucket J points to start of all the names begin with J. All data within same bucket are linked together
- Different versons of the same key are also linked to provide MVCC support. The begin/end time describes the transaction timestamp range when the value is valid and the range is strictly non-overlapping. All the reads have a read-time and only matching records would be returned.
During update, the record being updated has its end time marked with transaction id (Txn75 in the diagram) to indicating it is being updated, and any new record will have its start time to be the transaction id as well indicating it is a new record not being committed (the end time being infinity). Once the transaction commits, it updates the time to commit time. Old versions are garbage collected when they are no longer visible to any transaction, and done cooperatively by all worker threads.
Programming and Compilation
Typically DBMS use a “interpreter” style execution model to execute SQL statements. Hekaton compiler reuses SQL server T-SQL compiler stack (metadata, parser, name resolution, type derivation, and query optimizer). The output is C code and compiled with Microsoft VC++ into a DLL which gets loaded and executed at runtime.
As part of creation a new table, the schema functions such as hashing function, record comparison, and record serialization are compiled as well and available for index operations such as search / inserts. As a result those operation are quite efficient.
Ideally, these functions should be compiled together with SQL statements as well so that they can be properly inlined if needed, though the normal caveat of inlining applies.
A SQL statement is compiled into MAT (Mixed Abstract Tree) which is a rich abstract syntax tree representing metadata, imperative logic, and query plans. It is then converted into PIT (Pure Imperative Tree) that is more easily converted into C or other intermediate representations. The following picture shows the high-level flow:
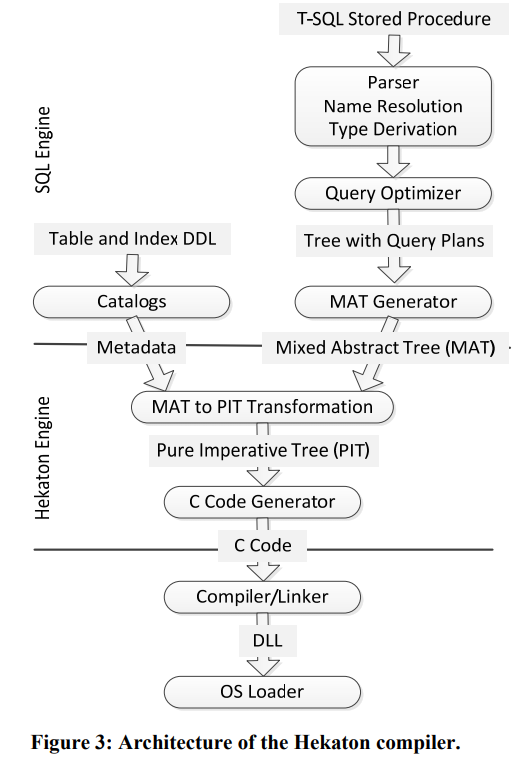
A query plan consists of a tree of operators, like most query execution engines. Each operator has a common interface of operations so that they can be composed. In the example, the code calls Scan Operator which calls Filter operator to filter on the list of rows. The operators are connected by gotos instead of making calls - this greatly reduces the overhead of passing parameters and procedure calls, though it makes debugging the code harder.
The gotos is effectively “inlining” the code by hard coding the gotos, is less efficient but simpler to implement. It is also reasonable to expect compilers to inlining the code since the call graph are well defined.
Not all code are compiled - some are available as helpers such as sorting, math, etc where the implementation are complex and the overhead of function calling are relatively low.
The compiled store procedure looks like just like any T-SQL store procedures and supports parameter passing. There are limitations to what those T-SQL procedures and the SQL statements can do due to implementation restrictions. To get around those limitations, Hektaon supports Query Interop that enables conventional disk based query engine to query memory optimized tables.
Transactions
Hekaton supports optimistic MVCC to provide snapshot, repeatable read, and serializable transaction isolation. For serializable transactions it ensures:
- Read stability - version still is the version visible at end of transaction
- Phantom avoidance - scan wouldn’t return additional new versions
It is worth noting that repeatable read only need read stability.
In order to validate the reads, transaction checks the versions it read are visible as of the transactions end time. Each transaction maintains read-set (a list of pointers to each version it has read), and a scan-set.
If transaction T1 sees data changes in T2, T1 takes a commit dependency on T2. Before T2 commits, T1’s result set is held back by a read barrier and will be sent to client as soon as it is cleared.
Technically this is still blocking since the client won’t be receiving the results back. However in theory the thread can be freed to process other transactions. Until then the transaction isn’t actually committed.
Once transaction’s update has been logged, it is irreversibility committed and during commit post processing phase it’ll update all end timestamps in all versions it touched to the end / commit timestamp of this transaction. The list of insert / deleted versions is maintained with a write-set.
During a rollback, all versions created in transaction will be invalidated. Delete version will be restored by clearing end timestamp (to infinite). Any transaction dependent will be notified.
Checkpoint and recovery
Hekaton ensures transaction durability that allows it to recover after a failure, using logs and checkpoints. The design minimizes transactional processing overhead and push work to recovery time if possible. It supports parallel processing during recovery. Index are reconstructed during recovery.
Logs are essentially redo log for committed transactions. No undo log is recorded.
Checkpoints are continuous, incremental, and append-only - they are essentially delta of changes recorded in sequential files, containing multiple data files and delta files. The reason they are contiuous is that periodic checkpoints are disruptive for performance. Data files contains inserted records covering a specific timestamp range, and loaded at recovery time and index reconstructed. Delta files are list of deleted versions in the data file and 1:1 maps to data file. At recovery time it filters out records in data files and avoid loading them into memory. They are loaded in parallel during recovery. In this sense, checkpoints are basically compressed log. Checkpoint data files are also merged to drop deleted versions.
The continuous nature of checkpoints is different than traditional checkpoints. In traditional checkpoints, no filtering is required because data that are deleted in the timestamp range would get dropped in the checkpoint process. However with continuous checkpoint you need to record both inserts and deletes. It is essentially a segmented log that is self-contained (so just rotating redo logs won’t work) and optimized for batch loading.
Garbage Collection
Hekaton GC removes versions that are no longer visible to any active transactions. It is non-blocking, parallelizable and scalable. Most interestingly it is cooperative - worker threads doing transactional process will discard versions when they encounter it, making it naturally scalable. There are also background dedicated GC worker threads as well, in order to collect cold regions of index that might not be scanned at all.
Hekaton GC locate garbage versions by looking for end stamp smaller than oldest active transaction timestamp, which is determined periodically by a GC thread scanning global transaction map.
The background collection thread breaks the work and send the work to a set of work queues. Once Hekaton worker thread is done with transactional processing it’ll pick up a small chunk of garbage collection work as its CPU-local queue. It naturally parallizes work across CPU cores and also self-throttle since it is done in worker threads.
What’s next
There are a few more related paper that we can explore. Bw-tree is probably the most interesting and worth looking into.