bloaty is a great tool from Google for binary size analysis. We were just wondering why the binary size became so large for our code in production and bloaty is great at that.
For example, if you run it against a release build of bloaty itself, just for fun:
You can easily tell most of the size is actually debug information - 79.2% (35.8+25.3+11.6+6.5)! This is actually a pretty common pattern for C++ binarie and most of the size is debug info. These debug symbols can be offloaded to a symbol package and installed on-demand for coredumps and debugging if needed, if size is becoming an issue.
Another interesting analysis you can do is to look at how much each file is contributing to your different sections (text, string, etc). Again, using bloaty itself as an example:
It looks like protobuf is a big contributor. Now we can add source filter to see how much:
./bloaty -d sections,compileunits --source-filter=protobuf ./bloaty
...
100.0% 24.1Mi 100.0% 1013Ki TOTAL
Filtering enabled (source_filter); omitted file = 21.1Mi, vm = 5.67Mi of entries
There are a lot of output here, but you can see protobuf contributs to 24.1/45.2=53% of size of bloaty itself. If you want you can also dive into different sections to see how much each individual files contributes to as well.
This came up during a code review and the code was using volatile to ensure the access to the pointer variable is atomic and serialized, and we were sort of debating whether it is sufficient, in particular:
Is it safer to switch to std::atomic<T>, and if so, why?
Is volatile sufficiently safe for a strong memory model CPU like x86?
Most of us can probably agree that std::atomic<T> would be safer, but we need to dig a bit deeper to see why is it safer, and even for x86.
This paper is the paper to read about Raft consensus algorithm and a good way to build intuition for consensus algorithms in general. The “consensus” about consensus algorithms is that they are hard to understand / build / test, and not surprisingly having an understandable consensus algorithm has a lot of value for system builders. I think Raft is designed for today’s mainstream single leader multi-follower log-replicated state machine model so it is a great starting point for building a practical distributed system around it. I’ve read about raft before but this is the first time I went through the paper in full. I must admit I find Paxos not intuitive and hard to follow as well and I might give Paxos/Multi-Paxos a go some other time. Meanwhile Raft is something I can get behind and feel comfortable with. And that is saying something.
It’s been a while since the last update - I was mostly focusing on database technologies. Beginning of the year 2021 is a bit slow (that’s when many big companies start their annual / semi-annual review process), so I had a bit of time to write up this post about 6502 CPU emulation. All the code referenced in this post is in my simple NES emulator github repo NesChan. It’s fun to go back and look at my old code and the 6502 CPU wiki.
The 6502 CPU
NES uses 8-bit 6502 CPU with 16-bit address bus, meaning it can access memory range 0x0000~0xffff - not much, but more than enough for games back in the 80s with charming dots and sprites. It is used in a surprising large range of famous vintage computers/consoles like Apple I, Apple II, Atari, Commodore 64, and of course NES. The variant used by NES is a stock 6502 without decimal mode support. It is running at 1.79HMZ (PAL version runs at 1.66MHZ). It has 3 general purpose register A/X/Y, and 3 special register P (status) /SP (stack pointer) /PC (program counter, or instruction pointer), all of them being 8-bit except PC which is 16-bit. NES dev wiki has a great section on 6502 CPU that has a lot more details and we’ll be covering the most important aspects in the remainder of the article.
In my personal C++ projects I’ve always been using doctest. It’s simply awesome. It takes a few seconds to get bootstrapped and you are ready to run your tests. And it should really be the first thing you do when you start a new project.
For example, I’ve been using it in neschan which is a NES emulator that I wrote for fun back in 2018, and one such example is a few unit test that validates the emulated 6502 CPU works correctly:
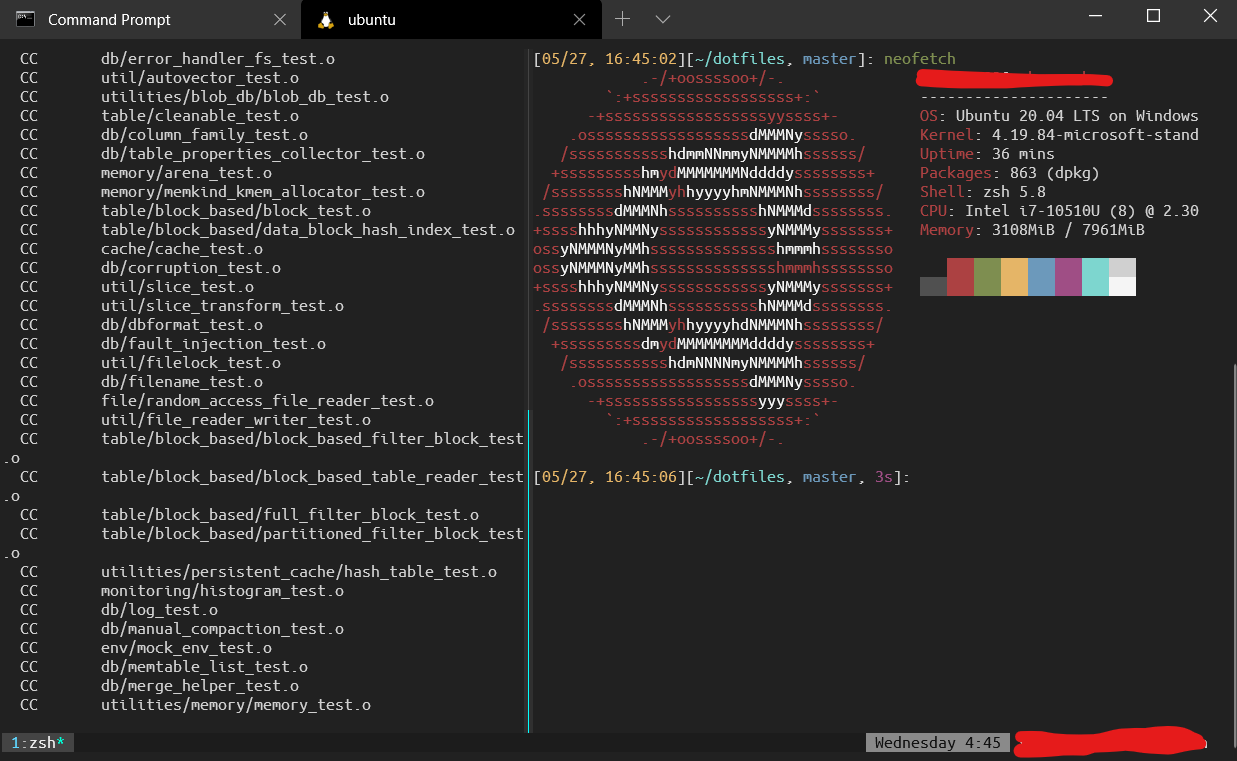
I’ve had a Lenovo X1 Carbon 7th gen for a while and tried putting Ubuntu 20.04 on it, but had quite a bit of trouble. Mostly the problem was this model has 4 speakers (two front and two bottom) so linux had quite a bit of trouble with it. The sound was tinny, and volume up / down doesn’t work either. The microphone jack also pops. There are other minor issues like finger print sensor doesn’t work, though I don’t care about it much. There is a long thread discussing problems with ubuntu. I spend quite a while browsing forums and find some work arounds, but none are satisifactory. So I gave up and went WSL2.
Paper summary for Hekaton paper describing SQL Server’s in-memory OLTP database
This is a great paper covering Microsoft Hekaton storage engine. There are a lot of meaty stuff here - lock-free Bw-tree indexing, MVCC, checkpointing, query compilation. I’m especially interested in its query compilation given my background in the .NET runtime and I’ve also spent some non-trivial amount of time focusing on optimizing query performance in my current job. Bw-tree is a very interesting direction for B+ tree as well and we’ll also be looking at a few papers that covers Bw tree in more depth in future posts.
I’ve been doing some research in this area trying to understand how this works in databases (for my upcoming project), so I thought I’d share some of my learnings here.
InnoDB internally uses ReadView to establish snapshots for consistent reads - basically giving you the point-in-time view of the database at the time when the snapshot it is created.
In InnoDB, all changes are immediately made on the latest version of Database regardless whether it has been committed or not, so if you don’t have MVCC, everybody will see the latest version of rows and it’ll be a disaster for consistency. Not to mention you’ll need to be able to rollback the changes. In order to achieve this, InnoDB maintains a undo log to track a link list of changes made by other transactions, so reading in the past with a snapshot means going from the latest record in the BufferPool, and walk backwards to find the first visible change. Rollback is similar.
This also means the undo log can’t be purged if the snapshot is still active, and undo log will get longer and longer, which slows down the reads more and more. This is the infamous long running transaction issue.
The fundamental issue is that you need to be able to determine visibility of changes. This is done with two things:
InnoDB tracks the trx_id_t of each rows and in the undo log
InnoDB internally use a data structure called ReadView to determine if a transaction is visible in the snapshot.
So the algorithm becomes as simple as walking the list backwards and find the first visible record.
The year of Linux desktop has finally come. It’s Windows + WSL 2. Seriously.
I use a MBP 16 for my daily work and SSH into linux machines for development/testing. While it’s a fantastic machine (and the track pad is second to none), I just hate the Apple trying to lock down the system so much that even setting up gdb to work is a nightmare, and running any simple script it tries to phone home for validation.
So I tried installing Linux on my machines. I do have a personal laptop X1 Carbon Gen7, but it doesn’t work well with Linux: mostly Linux just doesn’t like the 4 Channel Dolby Surround Speakers - they sound something from a tin-can and volume is much lower. While in Windows the sound I get is actually pretty nice (for a laptop, of course). I have spent countless time on it and I’ve seen many people struggling through the same issues. There are also occasionall hipcup with suspend/resume, but I can live with that. I also have a powerful gaming PC which I mostly play games. WSL sounds like a perfect solution for those machines where I can use Windows for their compatiblity / games, while also use it for development / tinkering on Linux. Yes, you can either dual boot or install a linux VM, but the integration between WSL 2 and Windows seems pretty nice to me, so I decided to try it out - and now all my Windows machines have WSL 2 installed.
Setting it up is not too bad - you do need to follow the official instructions to install it, which I’m not going to repeat here. The installation experience was fairly smooth, though it requires multiple steps.
However, to get it work properly requires a bit of extra work. Once you set it up it’s pretty much all I ever needed. Here is what it looks like when I’m done:
Anyone familiar with Python probably knew its history of Unicode support. If you add Python3, Unicode, and SWIG together, imagine what might go wrong?
Python3, Unicode, SWIG, and me
I was debugging a test failure written in Python just now and it is failing with this error:
Many of the end-to-end tests here are written in Python because they are convenient - no one wants to write a C++ code to drive MySql and our infra service to do a series of stuff.
UnicodeEncodeError: 'latin-1' codec can't encode character '\udcfa' in position 293: ordinal not in range(256)
The code seems straight-forward enough. The offending string looks like this: b"SELECT from blah WHERE col='\\372'.
This string was originally escaped by folly::cEscape which does simple thing rather simple - converts the string to be a C representation where ‘' are double escaped and any non-printable characters are escaped with octal. This is convenient as those escaped strings are safe to pass around without worry for encoding as they are, well, ASCII.
folly is Facebook’s open source standard C++ library collection. See https://github.com/facebook/folly for more information.
It is convenient, until you need to call from Python, for which you’ll need to use SWIG:
If you don’t know SWIG - just think it’s a tool that generates Python wrapper for C++ code so that they can be called from Python code. In this case, folly::cUnescape. Go to http://www.swig.org/ to learn more. Many language have equivalent tool/feature built-in, P/invoke in C#, cgo in go, JNI in Java, etc.
I was scratching my ahead trying to understand what is happening as there is no way the strings are converted to ‘\udcfa’, until I realize cUnescape might be at fault.
It turns out, SWIG expects UTF-8 string and returns UTF-8 strings back. “\372” can be converted to UTF-8 without any trouble, but once it is unescaped it becomes “\372” which is 0xfa that is going to be interpreted as UTF-8:
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT