Paper Reading: In Search of an Understandable Consensus Algorithm (Extended Version)
This paper is the paper to read about Raft consensus algorithm and a good way to build intuition for consensus algorithms in general. The “consensus” about consensus algorithms is that they are hard to understand / build / test, and not surprisingly having an understandable consensus algorithm has a lot of value for system builders. I think Raft is designed for today’s mainstream single leader multi-follower log-replicated state machine model so it is a great starting point for building a practical distributed system around it. I’ve read about raft before but this is the first time I went through the paper in full. I must admit I find Paxos not intuitive and hard to follow as well and I might give Paxos/Multi-Paxos a go some other time. Meanwhile Raft is something I can get behind and feel comfortable with. And that is saying something.
Overview
Paxos is quite difficult to understand and requires complex changes to support practical systems. Raft is designed to be significantly easier to understand than Paxos, simlar with Viewstamped Replication, but with some novel features:
- Strong leader with single direction of flow
- Leader election with randomized timers
- Membership changes with joint consensus
Consensus algorithms typicaly on a collection of state machines computing identical copies. Typically implemented separately with a replicated log, and executes in order. State machines are determinstic in nature and produces exact state.
Paxos has become almost synonymous with consensus (at the time of writing). Paxos first define a protocol capable of reaching agreement within a single instance, referred to as Single Decree Paxos, and then combine multiple instances to faciliate a series of decision. Paxos ensures both safety and liveness, but it has two main drawbacks:
- Exceptionally difficult to understand. From the paper:
In an informal survey of attendees at NSDI 2012, we found few people who were comfortable with Paxos, even among seasoned researchers. We struggled with Paxos ourselves; we were not able to understand the complete protocol until after reading several simplified explanations and designing our own alternative protocol, a process that took almost a year
- Not a good foundation to building practical implementations, mainly because multi-Paxos is not sufficiently specified, and as a result practical systems bear little resemblance to Paxos. One comment from Chubby implement is typical:
There are significant gaps between the description of the Paxos algorithm and the needs of a real-world system. . . . the final system will be based on an unproven protocol.
For these reasons, the authors designed an alternative consensus algorithms - and that is Raft. Raft is designed for understandability:
- Decomposing the problems into easy-to-understand/explain pieces independently, such as leader election, log replication, safety, and membership changes.
- Simplifying the problem space by placing constraints and reducing states, such as disallowing holes in logs.
Raft Consensus Algorithm
Raft implements consensus by first electing a leader who is responsible for managing the replicated log. Therefore, consensus algorithm can be broken down into 3 categories:
- Leader election - leader must be elected
- Log replication - leader replicates logs across cluster
- Safety
- Election safety: at most one leader can be elected in a given term
- Leader Append-Only: a leader never overwrites or deletes entries in its log; it only appends new entries
- Log Matching: if two logs contain an entry with the same index and term, then the logs are identical in all entries up through the given index.
- Leader Completeness: if a log entry is committed in a given term, then that entry will be present in the logs of the leaders for all higher-numbered terms.
- State Machine Safety: if a server has applied a log entry at a given index to its state machine, no other server will ever apply a different log entry for the same index.
The basics
Raft server is in one of 3 states:
- Leader - accept client requests
- Follower - accept requests from leaderes
- Candidate - used to elect new leader
Raft divides time into terms marked with monotonically increasing integers. Each term begins with election where one or more candidiates attempt to become leader.
Following diagram shows possible state transitions:
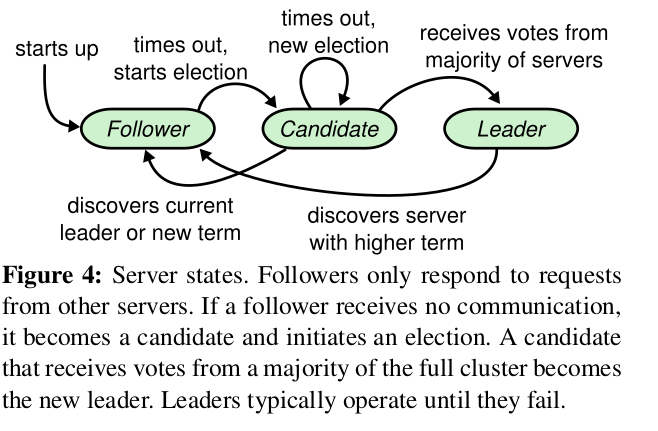
If one wins it becomes leader for the entire term. Otherwise in the case of split vote, the term ends with no leader. There is at most one leader in a given term. Term servces as Logical Clock in raft - each server maintains a current term that is monotically increased and exchanged when they communicate, and if stale term is detected server will update to the larger value. Server would reject requests with stale term.
Raft servers communicate with mainly two kinds of RPC:
- RequestVote RPC - initiated by candidate for leader election
- AppendEntries RPC - initiated by leaders to replicate to follower and provide heartbeat There is also a 3rd RPC for transferring snapshot. RPC are issued in parallel and will be retried if no ACK is received within time.
Leader election
Servers start up as followers, and will stay as leaders if they keep receiving AppendEntry RPC from leader or candidate. Leader send periodic empty AppendEntries RPC as heartbeat, so if followers aren’t receiving such heartbeat within a period of time (called Election Timeout), followers will start leader election.
As part of leader election, follower increments its current term and transition to candidate state, and then vote for itself and issue RequestForVote RPC in parallel to all the other servers.
A candidate wins election if it receives majority of votes. A server can only hand out vote for a single candidate in a given term and first come first serve basis. Once it wins election it’ll become leader and send empty AppendEntries RPC to all followers to establish authority and prevent new elections.
If candidate receives AppendEntries RPC from another leader, it only accepts it as leader if leader’s term >= its own term and return to follower state. Otherwise it rejects the RPC.
If many followers timeout and become candidate at the same time, it’s possible to have split vote situation and no one wins the election. In this case a new term of election is started. However, without extra measures the vote can continue infinitely, or only complete by luck. This is why Raft uses randomized timeout (for example, 150-300ms) to ensure split vote case are rare - so that followers timeout and become candidate at different time, and once split vote happens each candidate will start its own vote at different time.
The randomized approach might seem a bit naive at first glance, but the authors have debated a few different approaches and concluded that randomized timeout is the easiest to understand and prove correct:
From the paper:
lections are an example of how understandability guided our choice between design alternatives. Initially we planned to use a ranking system: each candidate was assigned a unique rank, which was used to select between competing candidates. If a candidate discovered another candidate with higher rank, it would return to follower state so that the higher ranking candidate could more easily win the next election. We found that this approach created subtle issues around availability (a lower-ranked server might need to time out and become a candidate again if a higher-ranked server fails, but if it does so too soon, it can reset progress towards electing a leader). We made adjustments to the algorithm several times, but after each adjustment new corner cases appeared. Eventually we concluded that the randomized retry approach is more obvious and understandable
Log Replication
Once client send request to the leader, leader sends AppendEntries RPC to all followers in parallel to replicate the log entry. Once it is safely replicated, leader will then apply the log entry to its own state machine and returns the result of that exception to the client. The request is retried indefinitely until all followers have ACKed.
A raft log entry consists of (term, index, operation). Leader decides when it is safe to apply the log entry to the statement and applying the operation, and such log entry becomes committed. Raft gurantees that committed entries are durable and will eventually replicate to all available state machines. A log entry is committed once it is replicated to the majority of the servers. All the precending entries are considered committed as well. Once a follower learns the log entry is committed, it applies the entry to its own local state machine in log order.
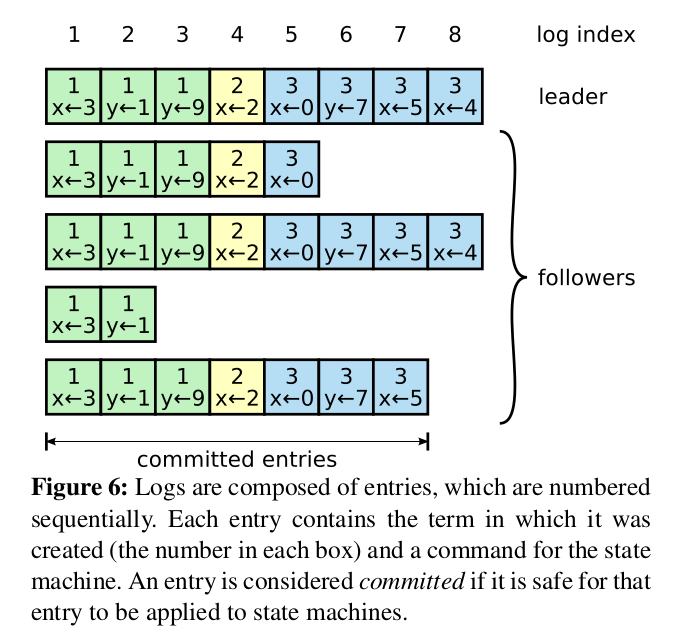
This implies the latency will be higher in a raft consensus system as the follower would have to know the log entry being committed, usually on the next AppendEntries RPC request (either real user request or heartbeat).
Raft maintains the Log Match Property:
- If two entries in different logs have the same index and term, then they store the same command.
- If two entries in different logs have the same index and term, then the logs are identical in all preceding entries.
This property makes Raft logs much easier to understand and reason about its correctness.
After leader crashes, follower logs may become inconsistent with leader log. The paper have discussed a few scenarios that we won’t repeat hre. Raft handles consistencies by follower log to duplicate with the leader’s log - so conflicting entries in follower log would need to be rewritten. This is done by finding the latest log entry that is consistent in follower, and delete any logs after that, and send all following entries after it. This is achieved by having the leader maintain nextIndex for each follower, and keep sending AppendRPC and decrease it if rejected, until they agree, and at that point follower log after nextIndex is deleted. This can be further optimized by having AppendEntries RPC return the first conflicting term and first index in the term so that the leader would skip conflicting entries.
If a candidate / follower crashes, the leader would just retry infinitely. If the server already inserted the log but didn’t ACK, raft RPC are idempotent so it’ll just get ignored.
Election Safety
To prevent a stale follower overwriting committed entries, there must be further restrictions on leader election.
A candidate cannot win an election unless it contains all committed entries. When it sends RequestVote with the latest (term, index) in the log, such request will be rejected by other servers if their latest log entry (term, index) is larger and therefore more up to date.
It’s also possible for leader replicating previous term log entries to other stale followers and making them committed, but doing so before committing the new term running the risk of having the newly committed entry getting overwritten if it crashes before then. So committing log entries from previous term is deferred until an entry from current term commits. Other consensus algorithms tries to address this by “fixing” prior term to latest term but Raft is keeping things simple by having the log entry being immutable and retain the term number.
In the paper 5.4.3 Safety Argument section the correctness is proven there. Feel free to refer to the paper for more details.
Cluster Membership Changes
When cluster membership changes (adding/removing server, etc), it is important to prevent having two leaders at the same time with old/new configuration. This needs to be done with a two-phase approach - raft first switch to a joint consensus that is both old and new, and once the joint consensus has committed then raft will transition to the new configuration.
In joint consensus,
- Log entries are replicated to both configurations
- Any server from either configuration may serve as leader
- Agreement requires separate majority from both old and new configuration - this means the log entry gets replicated in both configurations
Note the leader of joint consensus might not be part of the new cluster configuration. In this case it doesn’t count itself in the majority but still replicates to both majority, and step down once new configuration entry commits.
I’m wondering if’d be easier if we force the new leader to be the intersection of old configuration and new configuration.
When new server join the cluster, it might be a while for them to replicate all entries so new entries might not be able to proceed, so they need to join as non-voting members that is replicated but didn’t join the majority, until sufficiently caught up.
When removing servers from cluster, they will stop receiving heartbeats so they will start elections and disrupt the cluster availability. To prevent this problem, servers disregard RequestVote RPC within a minimum election timeout, and in such case the leader is considered alive. Note this isn’t the election timeout of the server (since it’ll revert to candidate if that happens) but rather a minimum “safe” election timeout. All the servers’s election timeout will be at least as large or larger than the minimum election timeout.
Other practical considerations
In any log system you can’t have the log grow unbounded, so raft needs to be able to compact the logs. In theory you could just create a snapshot of committed entries, but for a slow follower or a new server you would have to send the snapshot over with InstallSnapshot RPC. In practice terms this means discarding the state of the follower entirely, then copying the entire state over to the follower either physically or logically, and delete all logs. This is no different than incremental logging system such as LSM tree.
When client interacts with the cluster for the first time, it sends to a random server. If not the leader it’ll reject / forward to the correct leader. It is also possible that the leader crashes after commit but before ACK, so the client would retry the write again on a new leader which may have this entry. The client would need to track the request with a serial number so that the new leader can detect and return immediately.
For read-only queries, leader can only return the data once it commits its first blank AppendEntries RPC so that it is up-to-date and all entries are committed - it is still possible for uncommitted log entries from earlier term to become committed later (as part of catching up other followers), or those uncommitted changes can get discarded if another lead gets elected without those changes. It is also possible for the leader not knowing others might have elected a new leader, so the leader needs to confirm by exchanging heartbeat with majority of cluster before responding. Alternatively you could also use a lease-based approach but requires bounded clock skew.
My closing thoughts
Raft protocol has definitely delivered its promise on being a practical and understandable consensus procotol - the proliferation of many implementation in various languages has already proven that. And there are already many system using raft in production such as Kubernetes/etcd, CockroachDB, TiKV, etc. There are even raft support w/ MySQL from Alibaba. It’d be interesting to see how Raft performs in real production systems and how well does it scale in practice.